Overview
OpenHouse is an open-source control plane designed for efficient management of tables within open data lakehouse deployments. The control plane comprises a declarative catalog and a suite of data services. Users can seamlessly define Tables, their schemas, and associated metadata declaratively within the catalog. OpenHouse reconciles the observed state of Tables with their desired state by orchestrating various data services.
Control Plane for Tables
Following figure shows how OpenHouse control plane fits into a broader open source data lakehouse deployment.
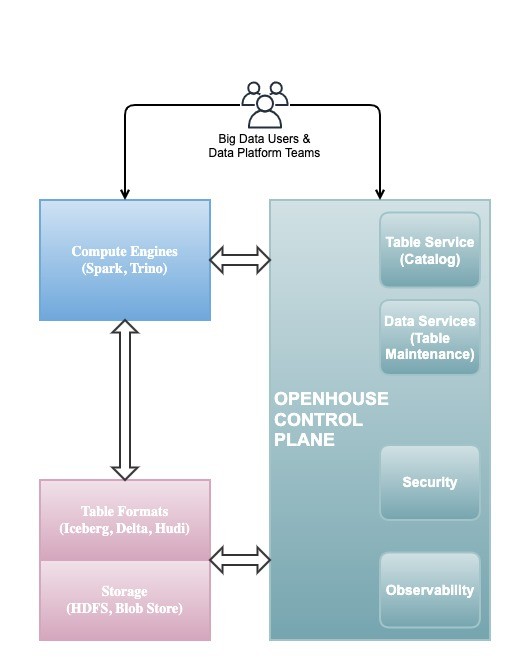
Catalog Service
The core of OpenHouse's control plane is a RESTful Table Service that provides secure and scalable table provisioning and declarative metadata management. The service exposes Tables as the RESTful resource which includes following metadata:
- Identifiers (Cluster ID, Database ID, Table ID, Table URI, Table UUID)
- Schema (Column Name, Column Type, Column Comment)
- Time Partitioning and String Clustering (Column Name)
- Table Policies (Retention, Sharing, Tags)
- Table Type (Primary, Replica)
- Other Metadata (Creator Principal, Created Time, Last Modified Time, and Version)
Data Services
Jobs Scheduler and Jobs Service are the two components that are responsible for orchestrating the execution of data services. Data services are designed to be modular and can be extended to support various data management operations.
Jobs Scheduler
Jobs Scheduler is responsible for iterating through all the tables, and for each table, it triggers a set of jobs (i.e. data services) to keep the table in a user-configured, system-defined, and compliant state. Job scheduler can be run as a cronjob per job type. It integrates with the Catalog Service to get the list of tables and corresponding metadata. It triggers the corresponding job by calling the Jobs Service endpoint. For example, if a table has a retention policy of 30 days, Jobs Scheduler will trigger the Job Service with the table name and retention period.
Job types supported today are described below:
- Retention
- Users can establish retention policies on time-partitioned tables. Retention job automatically identifies and delete partitions older than the specified threshold.
- Iceberg Snapshot Expiration
- Iceberg tables can have a retention policy on the snapshots. This job type is responsible for deleting the snapshots older than the specified threshold.
- Iceberg Orphan File Deletion
- Iceberg tables can have orphan files that are not referenced by any snapshot. This job type is responsible for identifying and staging them for deleting in a trash directory.
- Staged File Deletion
- All the staged files that are marked for deletion are deleted by staged file deletion job.
- Data Compaction
- This job type is responsible for compacting the small files in the table to improve the query performance and optimally use the assigned file quotas.
Jobs Service
All the job types discussed in Jobs Scheduler are implemented as Spark applications, and it is the Jobs Service that is responsible for submitting these jobs to the Spark cluster. Jobs Services is a RESTful service that provides an endpoint for the scheduler to trigger a job. Jobs Service is modularized in a way that it can be extended to support various spark job submission APIs. One such implementation based on Apache Livy API is shipped with the repository, and is used in docker compose setup.
Jobs Service also tracks all the job metadata, including the status of the job, the time it was triggered, table name, table metadata, error logs, and job type. This metadata is used for tracking job completions, observability and monitoring purposes at table granularity.
House Table Service
House Table Service is an internal RESTful service used by Catalog Service and Data Services. The backend storage for House Table Service is pluggable, and can use a Database supported by Spring Data JPA. The default implementation uses H2 in-memory, but it can be extended to use other databases like MySQL, Postgres, etc.
Engine Integration
OpenHouse is designed to integrate with various engines like Spark, Trino, and Flink at their Catalog layer. For Iceberg tables, OpenHouseCatalog implementation is provided to integrate with Spark. Given OpenHouse supports Table Sharing and Policy Management through Spark SQL syntax, SQL extensions are created, and implemented in the OpenHouseCatalog.
The integration on the engine side is anticipated to utilize a lightweight REST client for communication with the Catalog Service.
Trino and Flink engines follow a similar pattern of integration with OpenHouse and are work in progress.
Deployed System Architecture
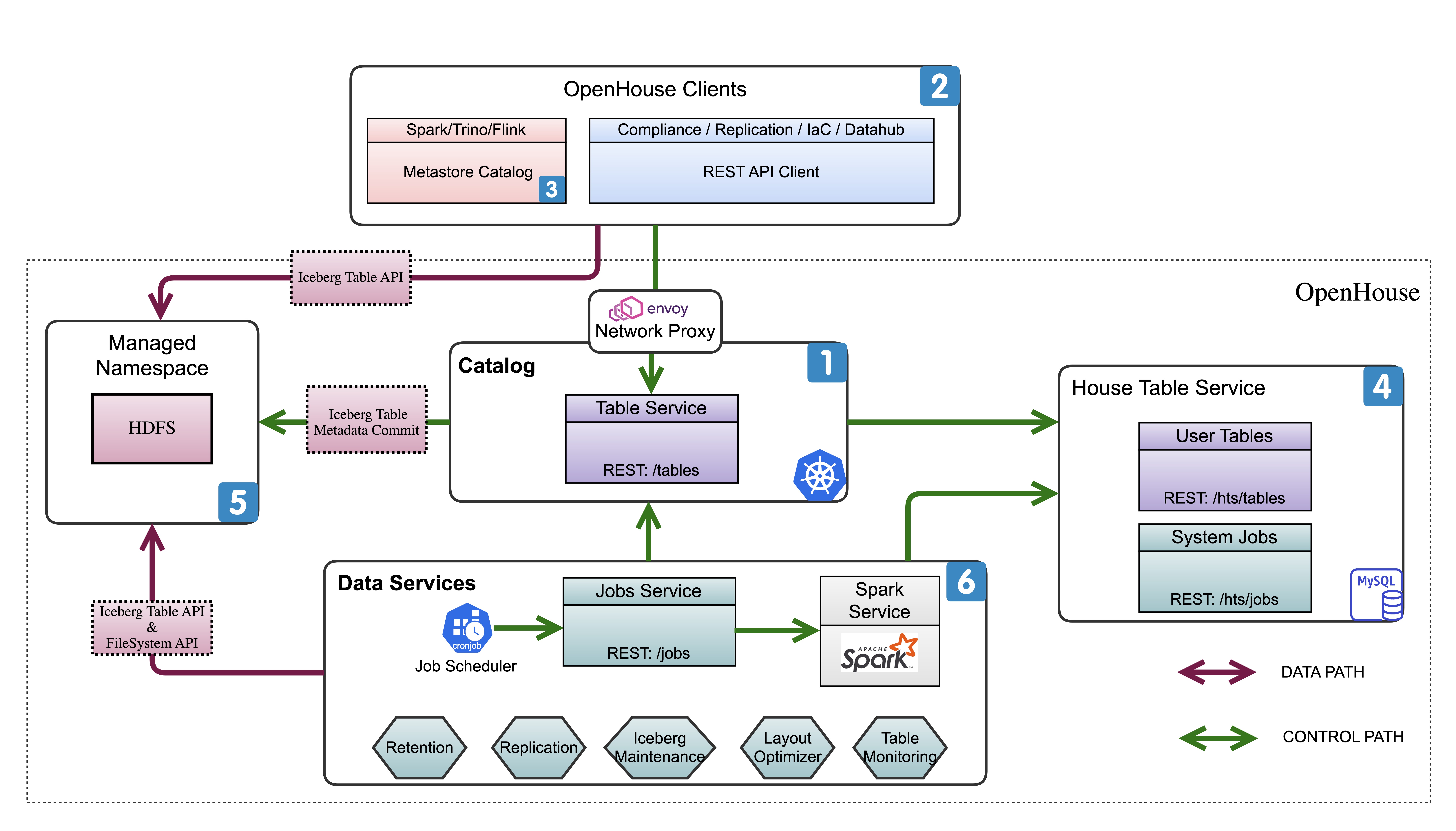
The figure above shows system components of OpenHouse deployed at LinkedIn. Each component is numbered and its purpose is as follows:
[1] Catalog (/Table) service: This is a RESTful web service that exposes tables REST resources. This service is deployed on a Kubernetes cluster with a fronting Envoy Network Proxy.
[2] REST clients: A variety of applications use REST clients to call into table service (#1). Clients include but are not limited to compliance apps, replication apps, data discovery apps like Datahub and IaC, Terraform providers, and data quality checkers. Some of the apps that work on all the tables in OpenHouse are assigned higher privileges.
[3] Metastore Catalog: Spark,Trino, andFlink engines are a special flavor of REST clients. An OpenHouse specific metastore catalog implementation allows engines to integrate with OpenHouse tables.
[4] House Database (/Table) service: This is an internal service to store table service and data service metadata. This service exposes a key-value interface that is designed to use a NoSQL DB for scale and cost optimization. However the deployed system is currently backed by a MySQL instance, for ease of development and deployment.
[5] Managed namespace: This is a managed HDFS namespace where tables are persisted in Iceberg table format. Table service is responsible for setting up the table directory structure with appropriate FileSystem permissioning. OpenHouse has a novel HDFS permissioning scheme that makes it possible for any ETL flow to publish directly to Iceberg tables and securely into a managed HDFS namespace.
[6] Data services: This is a set of data services that reconciles the user / system declared configuration with the system observed configuration. This includes use cases such as retention, restatement, and Iceberg-specific maintenance. Each maintenance activity is scheduled as a Spark job per table. A Kubernetes cronjob is run periodically on a schedule to trigger a maintenance activity. All the bookkeeping of jobs is done in House Database Service using a jobs metadata table for ease of debugging and monitoring.
Pluggable Architecture
Components of OpenHouse are designed to be pluggable, so that OpenHouse can be deployed in diverse private and public cloud environments. This pluggability is available for the following components:
- Storage: OpenHouse supports a Hadoop Filesystem interface, compatible with HDFS and blob stores that support it. Storage interfaces can be augmented to plugin with native blob store APIs.
- Authentication: OpenHouse supports token-based authentication. Given that token validation varies depending on the environment, custom implementations can be built according to organizational needs.
- Authorization: OpenHouse Table Sharing APIs can be extended to suit organizational requirements, covering both metadata and data authorization. While we expect implementations to delegate data ACLs to the underlying storage (e.g., POSIX permissions for HDFS), for metadata role-based access control, we recommend the use of OPA.
- Database: OpenHouse utilizes a MySQL database to store metadata pointers for Iceberg table metadata on storage. Choice of DB is pluggable, using Spring Data JPA framework, offers flexibility for integration with various database systems.
- Job Submission: OpenHouse code ships with Apache Livy API for submission of Spark jobs. For custom managed spark services, jobs services can be extended to trigger spark applications.
OpenHouse Cluster Configuration Spec is the place where all the configurations are defined for a particular cluster setup.